Side Channel Analysis (SCA) attacks generally speaking consisting of three phases: acquisition, pre-processing and analysis. The time it takes to extract a key from an embedded devices is the sum of these three phases combined. In our previous blog posts about Power Analysis and Electromagnetic Analysis, we discussed how we extracted the key from the ESP32’s hardware AES accelerator. In this blog post we discuss in more details how we were able to perform a super fast acquisition using our Piscoscope oscilloscope.
The time required for the acquisition phase depends on the overall time needed for performing repeated cryptographic operations. The cryptographic operation itself may be fast, like it typically is for a hardware implementation, other factors may slow down the acquisition speed significantly. For instance, if the interface towards the cryptographic operation is slow (e.g., a reboot is required every so many operations), then the acquisition speed is going to be affected negatively. However, often, at least under certain conditions, the hardware cryptographic accelerator can be accessed directly by writing into its registers. In such case, the implementation may not be the bottleneck, but rather the approach that’s taken for communicating with the target and acquiring the traces.
The time required for the pre-processing phase depends on the actual processing to be performed. For example, an unprotected cryptographic implementation, often does not need any pre-processing whatsoever. On the other hand, a protected cryptographic engine may require alignment or other pre-processing steps, aimed at increasing the signal to noise ratio (SNR), before performing the analysis. Of course, besides the pre-processing operations themselves, the amount of traces being processed has an impact on the overall pre-processing time.
The time required for the analysis phase mostly depends on the computations being performed, e.g., Correlation Power Analysis (CPA), as well as the amount of traces.
It’s important to point out that the acquisition phase depends on the target, while the pre-processing and analysis phases are performed off-target. In other words, the highest acquisition speed achievable is defined by the target’s speed, while the highest pre-processing/analysis speed achievable is defined by the speed of the software that’s used. The goal of a fast and efficient acquisition test bench minimizes the overhead during the overhead during the acquisition, pre-processing and analysis phase.
Our approach for speeding up the acquisition phase, compared to traditional methods typically used by academia and industry, was already described in our previous blog posts on SCA attacks. It’s important to point out that we did not invent this approach ourselves. It’s actually a standard oscilloscope feature as pointed out by Keysight and Picoscope. Others have used the same or similar techniques to speed up their acquisition speed for their own interesting research endevours: Schneider et. al., Moschos et. al., Haas et. al. and tihmstar among others. Moreover, industry tooling like Riscure’s Jlsca supports it too. In this blog post we shine yet another light on how fast cryptographic operations really can be measured.
Segmented Memory
The typical method for acquiring a measurement during a cryptographic operation is to perform the following
- Arm the scope
- Send the input data
- Set a signal, e.g., a GPIO pin
- Start the cryptographic operation
- Obtain the output data
- Receive measurement from scope
- Go to step 1
After the cryptographic operation is completed, the measurement is sent back to the computer and available for the pre-processing and analysis phases. With such an approach, it’s possible to acquire millions of traces per day, which is often sufficient for extracting a key from an unprotected target.
The time required for a single encryption performed with the ESP32’s hardware AES accelerator is shown below and is about 3μs. The red signal is a GPIO pin that’s set high just before the API call to start the cryptographic engine and set low when this API call returns. Such signal is commonly referred to as a trigger.
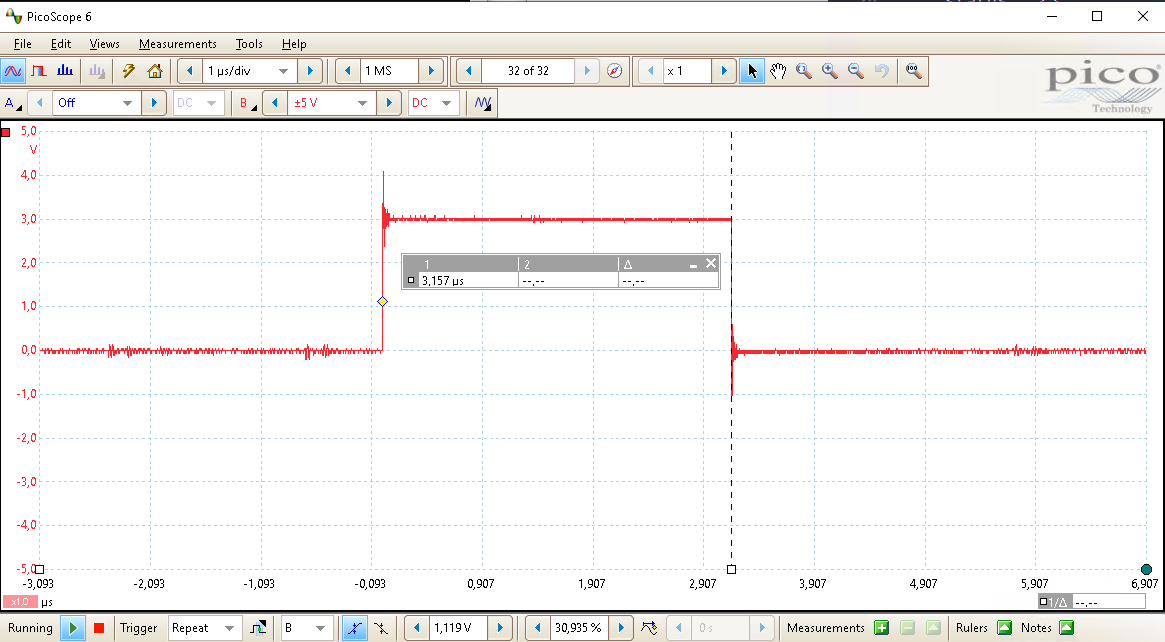
The time between two consecutive cryptographic operations (i.e., the overhead) is quite significant, i.e., about 16ms) as shown in the picture below. In other words, each measurement takes roughly 16ms to complete, even though the cryptographic operation only takes a fraction of that.
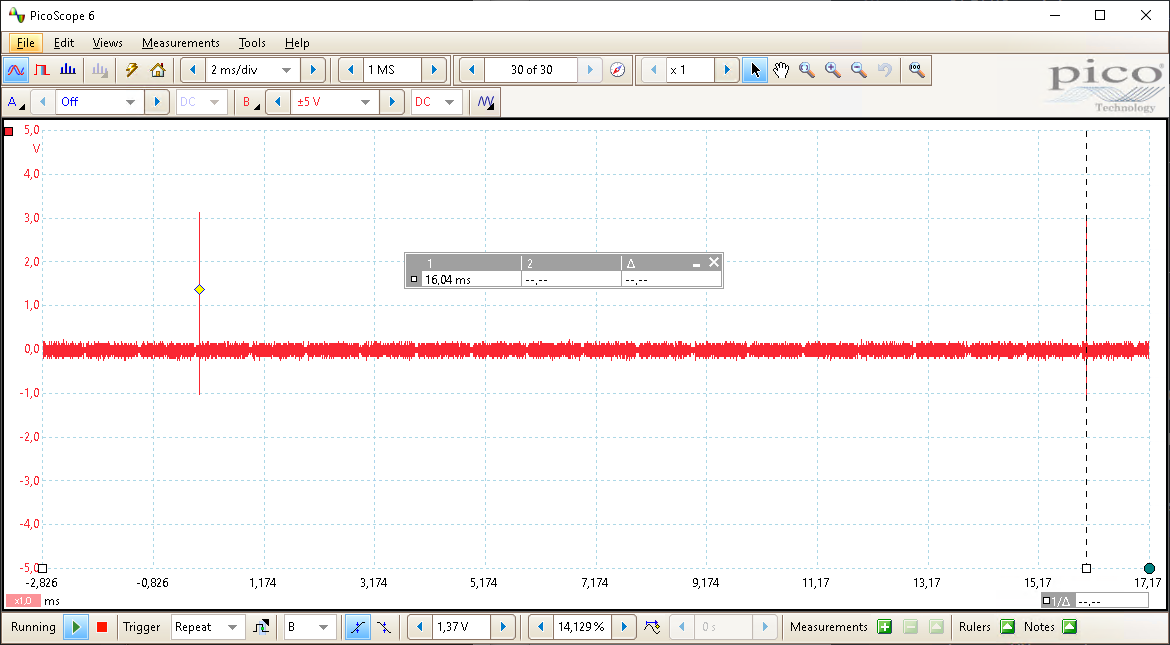
Needless to say, even though often sufficiently fast, in some situations, one cannot afford to wait a day, or, the leakage is so minimal that many millions of traces may be required for extracting the key. Hence, a faster acquisition speed is required. The most significant slow-down for this approach is the overhead introduced by the communications that occurs for each of the measurements. This includes both the communications with the oscilloscope and the communications with the target.
Interestingly, most oscilloscopes, support an efficient acquisition mode, referred to by Keysight as Segmented Memory Acquisition and by Picoscope as Rapid Block Mode. In such modes, the internal memory of the oscilloscope is segmented, i.e., divided in multiple segments, where each segment can be used to store a single measurement. This enables a user to measure multiple cryptographic operations that are all stored inside the oscilloscope’s internal memory. Even better, the user can define which samples, before or after the trigger, are to be stored for each of the measurements being performed. This allows the user to only store the relevant samples, i.e., the samples that leak, into dedicated segments. Then, once the internal memory is filled up, the measurements are communicated back to the user’s computer system. This minimizes both the overhead of communicating with the oscilloscope and the overhead of communicating with the target.
By using segmented memory, the time between two consecutive cryptographic operations, as is shown in the picture below, can be significantly reduced to less than a μs compared to the 16ms of a singular acquisition.
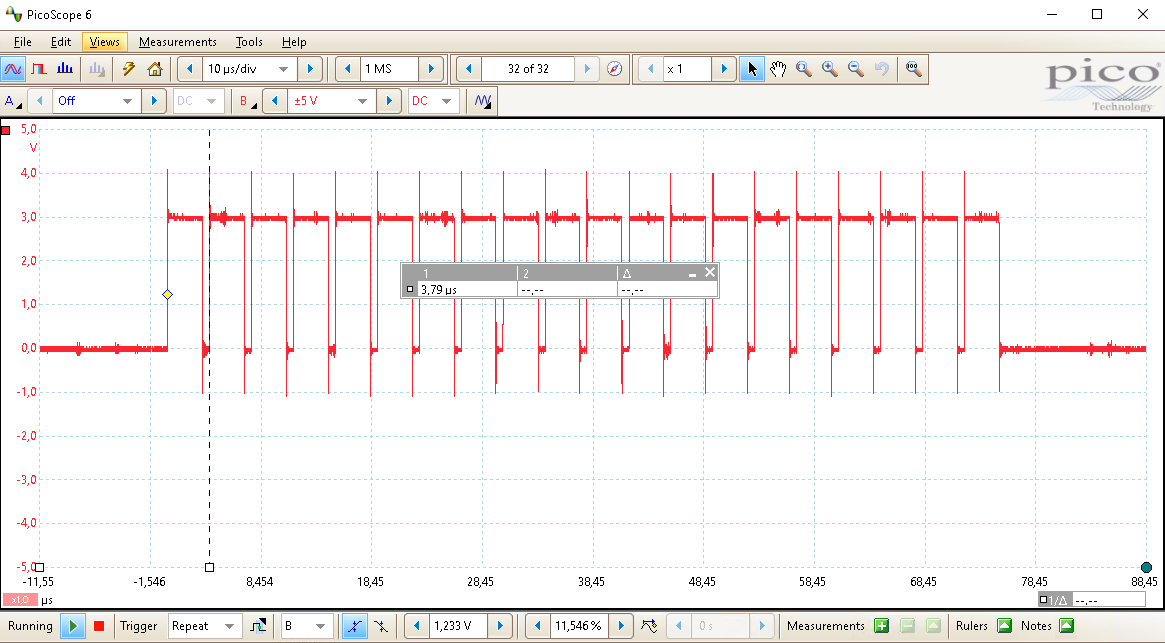
Of course, the overhead of communicating still needs to be added, as the segmented buffers need to be retrieved from the oscilloscope. As is visible in the picture below, the overhead between two consecutive batches of cryptographic operations is still similar, even though in absolute time forty (40) cryptographic operations have been performed instead of two (2).
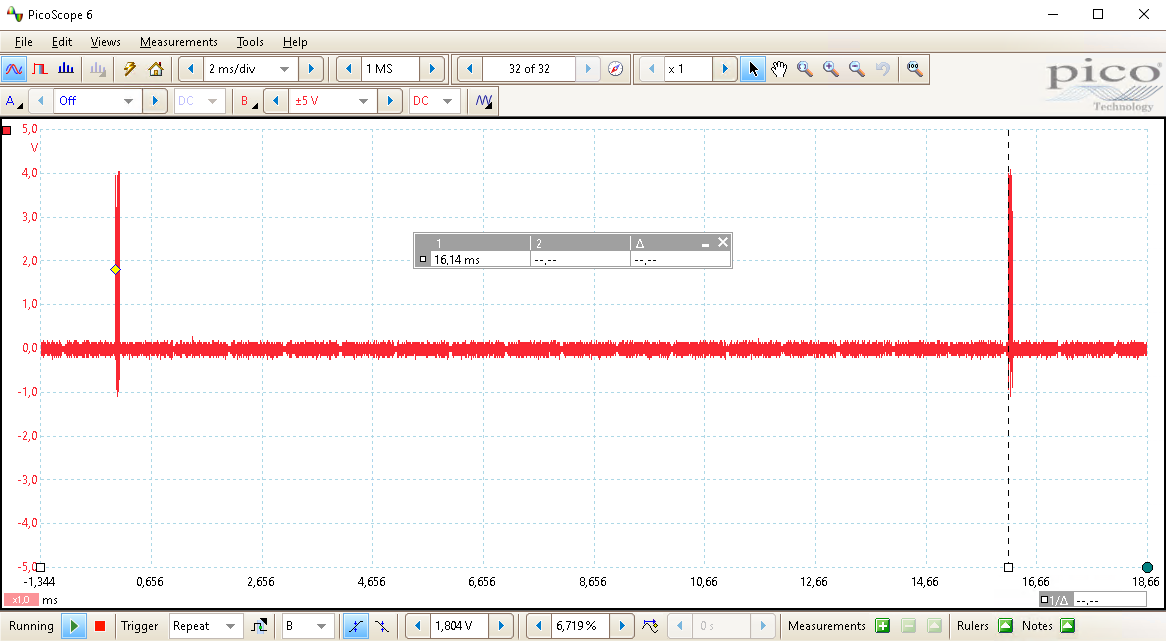
Note, the number of performing twenty (20) cryptographic operations, of which the measurement is stored in twenty (20) segments, is just taken as an example. Depending on the amount of samples to be measured, one can segment the internal memory of an oscilloscope into thousands of buffers. A memory depth of many million samples is not unlikely for a modern multi-purpose oscilloscope like our Picoscope 3206d. This means, that if the cryptographic operation is sufficiently short (i.e., less than 1000 samples), one can store thousands of measurements before returning the data back to the user, significantly reducing the communication overhead.
Input/Output Data
When performing an SCA attack, the input data you provide to it should conform to the type of attack to be performed. The standard SCA attack requires uniformly distributed input data, whereas more advanced attacks may require carefully chosen input data. We consider these more complex approaches out of scope, even though more complex input requirements do not necessarily void the findings described in this blog post.
For the standard SCA attack, where uniformly distributed input data is required, one can decided to randomize it for each cryptographic operation or keep it the same for a certain amount. Measuring multiple cryptographic operations with the same, yet still random, input data, allows for averaging the acquired traces. Such averaging allows for increasing the SNR as it’s assumed most of the noise is somewhat uniformly distributed while the signal is not as the input data and key are the same.
When there are no requirements for speed, it’s perfectly fine to generate the input data off-target on a computer system. However, when speed is important, and multiple cryptographic operations are stored in the segmented memory of the oscilloscope, it becomes preferred to generate the input data on the target itself. This removes the communication overhead introduced to provide input data from the computer system to the target for each cryptographic operation.
We decided to use the ESP32’s hardware AES accelerator as a PRNG to generate input data at the same time we are attacking it. This means that the output of the AES operation that we are attacking is used as input for the next AES operation. We only provide the target a 128-bit value that’s used as the input, i.e., seed, for the first AES operation. The code we used for implementation this approach is shown below.
...
for(int i= 0; i < iterations; i++) {
GPIO_OUTPUT_SET(26,1);
ets_aes_crypt(input, input);
GPIO_OUTPUT_SET(26,0);
}
...
To the best of our knowledge, this may be the first time that this approach is used like this. We are confident, as our initial seed is sampled from a sufficiently random source, that the outputs of the AES operation are sufficiently random to perform most SCA attacks. Please let us know if we missed in any way, any academia or industry researchers, utilizing this approach already.
Speedy Gonzalez
So, how fast can we really go? Well, of course, the title of this blog post gave it away. However, needless to say, the speed is determined by a wide variety of variables, which can all be considered, but that will be a time consuming activity. Therefore, we like to just talk about the speeds we obtained while measuring the ESP32’s hardware AES accelerator. Note, we only performed AES-128 encryption operation, no decryption operations and we did not perform any AES-256 operations.
The ESP32 chip’s AES accelerator encryption operation takes between 11 and 15 clock cycles. This means, if it would be clocked at 100 MHz, it should be possible to perform 576 billion operations per day. However, as you can imagine, we have to consider the overhead of interfacing with the hardware as well as the communication with both the target and the scope. Using the ROM API of the ESP32 chip, we were able to perform a single encryption in about 3.2μs as is demonstrated earlier in this blog post. We set for ourselves the goal to reach the maximum speed of 27 billion measurements per day (i.e., number of microseconds in a day divided by 3.2).
The tables below showcases the acquisition speeds we achieved under various conditions. We tested the speed for different sample sizes and with both averaged and non-averaged traces. All measured for all experiments at 500 MSa. The speed for storing the traces to disk with averaging is shown below.
| Experiment | Samples | Averaged | Nr Of Segments | Speed Per Day |
|---|---|---|---|---|
| A1 | 1600 | No | 1 | 5.34E+06 |
| A2 | 1600 | Yes | 10 | 1.68E+06 |
| A3 | 500 | Yes | 1000 | 1.16E+09 |
| A4 | 200 | Yes | 4000 | 2.64E+09 |
| A5 | 100 | Yes | 8000 | 4.17E+09 |
| A6 | 10 | Yes | 16000 | 7.57E+09 |
| A7 | 1 | Yes | 64000 | 8.55E+09 |
The acquisition speed is higher for averaged traces for most trace sizes as less data needs to be written to disk and no on-target data generator is required. The speed for storing the traces to disk without averaging is shown below. As you can see in the table, at some point the speed does not drastically increase any more, likely caused by the bottleneck of writing to disk.
| Experiment | Samples | Averaged | Nr Of Segments | Speed Per Day |
|---|---|---|---|---|
| B1 | 1600 | No | 1 | 5.34E+06 |
| B2 | 1600 | No | 10 | 1.68E+06 |
| B3 | 500 | No | 1000 | 1.39E+09 |
| B4 | 200 | No | 4000 | 1.70E+09 |
| B5 | 100 | No | 8000 | 1.80E+09 |
| B6 | 10 | No | 16000 | 1.92E+09 |
| B7 | 1 | No | 64000 | 1.94E+09 |
Note, we selected the number samples and number of segments manually, without too much consideration. It’s likely possible to optimize these numbers in a way to achieve higher speeds, even with the equipment available to us (i.e., Picoscope 3204d and a modern computer system). We are confident that with a high-end scope, that supports faster means of communication, and a faster computer system, it should be possible to get closer to the upper bound of 27 billion measurements per day.
Impact
If it’s possible to measure billions of cryptographic operations per day, should a hardware cryptographic accelerator be considered sufficiently hardened, when it’s demonstrated to be impossible if the keys cannot be extracted with only millions of measurements? Well, probably not, especially considering most attackers will be willing to measure for multiple days if that would yield information about a secret key they are after.
With the approach outlined in this blog post, we have been able to acquire more than a billion measurements in a single day. Therefore, we believe, that a statement like, “reveal no leakage beyond 100 million traces”, may actually not carry as much weight one may think. Manufacturers should really thoroughly investigate if there is also no leakage when traces sets are used of many billions of traces compared to millions.
Final words
Even though we were already aware that leveraging an oscilloscope’s segmented memory would yield higher acquisition speeds, we were surprised about the speed we actually achieved. Of course, in the light of the ESP32 chip, as we already demonstrated in our previous blog posts, these type of speeds may be completely unnecessary. However, depending on the task at hand, these type of speeds may be relevant for both unprotected implementations like found in the ESP32 chip and of course protected implementations.
We found this very high acquisition speed very useful for identifying good locations to place our EM probe. The overhead of testing multiple locations is significant when you want to test all locations in a 30x30 grid. Differently said, if the acquisition takes about a day at each of those locations, performing at all these 900 locations takes almost three (3) years. In such situation, speeding up the acquisition phase by a factor 1000 is likely crucial for doing it in reasonable time.
Protected cryptographic accelerators typically aim to minimize the signal-to-noise (SNR) ratio. Like previously mentioned, if you’re unable to find sufficient leakage with millions of measurements, maybe sufficient leakage can be found with billions of measurements, or even trillions. To the best of our knowledge, this technique, which enables attackers to acquire trace sets consisting of a substantial amount of traces, and its implications, are not often discussed thoroughly.
This acquisition approach is not necessarily voided by protected implementations that require alignment due to, e.g., random delays. We like to point out that such protected implementations still need to be sufficient and therefore the manufacturer cannot afford to randomly stretch the cryptographic operation too much. As our numbers have shown, we still manage to achieve speeds above 1 billion of traces per day when we are measuring 500 samples, which will easily encompass a protected implementation that is 10 to 50 times slower than an unprotected implementation. One can envision that, the pre-processing step for aligning the traces can be done in parallel to the acquisition, as long as each measurements is long enough to compensate for the misalignment. In other words, the pre-processing step may not affect the acquisition speed at all.
Even though we did not really approach the upper bound of 27 billion measurements per day, we believe it should be possible to get closer to this number. In fact, one can envision custom equipment that’s able to stream the measurements directly to super fast storage. This likely requires very expensive equipment that’s certainly not available to most attackers. However, this is likely an approach manufacturers of hardened implementations may want to consider to verify if there is any leakage.
Feel free to reach out for questions or remarks related to this research. As always, we are available to give training on the research we perform, during which you will gain hands-on experience exploiting the vulnerabilities described in this blog post.
- Raelize.